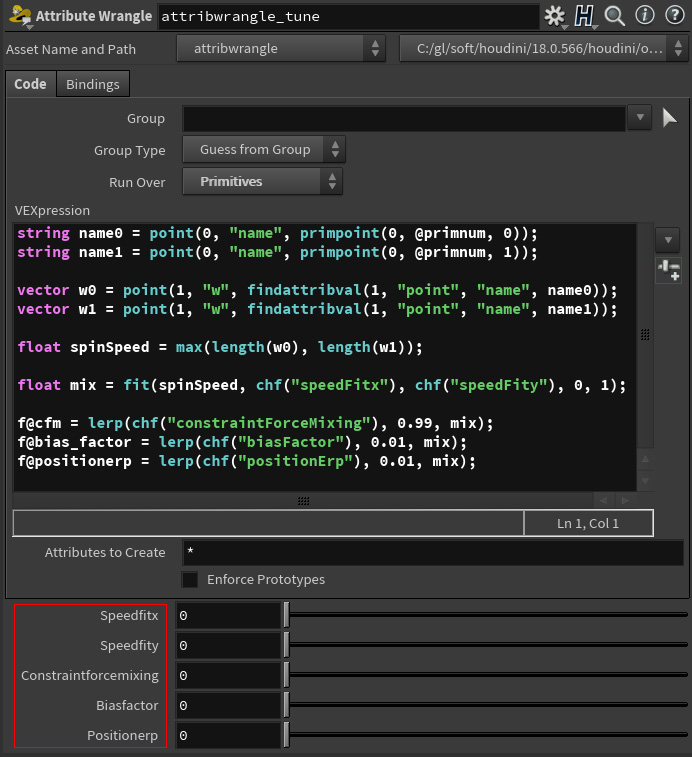
Camel is a tool for VEX snippets and any other nodes with a custom interface.
It helps format the labels for new parameters if they were written in camel case. Camel also merges parameters into a vector (if they have x, y, etc. characters at the end of the name).
With this tool, you can format the node interface with two clicks: create spare parameters and launch Camel.
You can download Camel here and bind it to the shelf, or use the next source code:
import hou
import re
def camel():
skipTypes = [hou.parmTemplateType.FolderSet,
hou.parmTemplateType.Folder,
hou.parmTemplateType.Separator]
camel = re.compile('^[a-z].*[A-Z]')
xyzwString = 'xyzw'
nameXYZW = re.compile('(.+)([{}])'.format(xyzwString))
for node in hou.selectedNodes():
templategroup = node.parmTemplateGroup()
spareTuples = []
houTuplesXYZW = {}
for parm in node.spareParms():
houTuple = parm.tuple()
template = houTuple.parmTemplate()
if nameXYZW.match(houTuple.name()) and len(houTuple) == 1 and \
(template.type() == hou.parmTemplateType.Float or template.type() ==\
hou.parmTemplateType.Int):
key = nameXYZW.search(houTuple.name()).groups()[0]
if key not in houTuplesXYZW:
houTuplesXYZW[key] = []
houTuplesXYZW[key].append(houTuple)
elif template.type() == houTuplesXYZW[key][-1].parmTemplate().type() and \
houTuple not in houTuplesXYZW[key]:
houTuplesXYZW[key].append(houTuple)
for key in houTuplesXYZW.keys():
houTuplesSolid = []
charTuplesDict = {}
for houTuple in houTuplesXYZW[key]:
char = nameXYZW.search(houTuple.name()).groups()[1]
charTuplesDict[char] = houTuple
for char in xyzwString:
if char in charTuplesDict:
houTuplesSolid.append(charTuplesDict[char])
else:
break
if len(houTuplesSolid) > 1:
parmsValues = {}
for houTuple in houTuplesSolid:
parm = tuple(houTuple)[0]
parmsValues[parm.name()] = parm.eval()
newTemplate = houTuplesSolid[0].parmTemplate().clone()
newName = nameXYZW.search(newTemplate.name()).groups()[0]
newLabel = nameXYZW.search(newTemplate.label()).groups()[0]
newTemplate.setName(newName)
newTemplate.setLabel(newLabel)
newTemplate.setNumComponents(len(houTuplesSolid))
newTemplate.setNamingScheme(hou.parmNamingScheme.XYZW)
firstTemplate = houTuplesSolid.pop(0).parmTemplate()
templategroup.replace(firstTemplate.name(), newTemplate)
for houTuple in houTuplesSolid:
templategroup.remove(houTuple.parmTemplate().name())
for parmName in parmsValues.keys():
node.parm(parmName).set(parmsValues[parmName])
node.setParmTemplateGroup(templategroup)
for parm in node.spareParms():
if parm.tuple() not in spareTuples:
spareTuples.append(parm.tuple())
for spareTuple in spareTuples:
template = spareTuple.parmTemplate()
if template.type() not in skipTypes:
name = spareTuple.name()
if camel.match(name):
splittedLabel = re.split(r'([A-Z]+)', name)
words = [splittedLabel.pop(0).title()]
words += [splittedLabel[n] + splittedLabel[n + 1] for n in \
range(0, len(splittedLabel), 2)]
template.setLabel(' '.join(words))
templategroup.replace(template.name(), template)
node.setParmTemplateGroup(templategroup)